Chỉ trong vài tuần, mô hình DeepSeek R1 đã làm chao đảo thị trường chứng khoán Mỹ và khiến OpenAI phải đối mặt với một đối thủ đáng gờm. Sự xuất hiện của nó đã xóa sổ 1 nghìn tỷ USD giá trị vốn hóa trên toàn thị trường, trong đó riêng Nvidia đã mất tới 600 tỷ USD. Mặc dù một số cổ phiếu đã phục hồi, nhưng rõ ràng DeepSeek đã tạo ra một tác động lớn đến các công ty điện toán và AI hàng đầu.
Với những tuyên bố gần như khó tin về chi phí huấn luyện mô hình chỉ bằng một phần nhỏ so với OpenAI, đồng thời bán quyền truy cập API với giá thấp hơn đáng kể, DeepSeek đã làm điều đó như thế nào? Điều gì đã thực sự xảy ra? Có rất nhiều điều cần phân tích ở đây, đặc biệt là xung quanh các tuyên bố của DeepSeek, những phản ứng từ các đối thủ, và việc tuyên bố R1 là “mã nguồn mở” liệu có nói lên toàn bộ sự thật.
DeepSeek R1 và DeepSeek V3: Hai Mô Hình, Một Tầm Ảnh Hưởng Lớn
Giới thiệu DeepSeek R1 và DeepSeek V3
Đầu tiên và quan trọng nhất, DeepSeek đã phát hành hai mô hình: V3 và R1. Cả hai đều đóng vai trò quan trọng trong câu chuyện này, nhưng trọng tâm thảo luận chủ yếu xoay quanh R1. DeepSeek R1 là mô hình suy luận (reasoning model) của công ty, có khả năng tự đặt câu hỏi và tự đối thoại với chính nó trước khi đưa ra câu trả lời cho một truy vấn, tương tự như mô hình o1 của OpenAI.
DeepSeek V3 là một mô hình ngôn ngữ lớn (LLM) đa năng, sử dụng kiến trúc Mixture of Experts (MoE) với 671 tỷ tham số. DeepSeek R1 được xây dựng dựa trên DeepSeek-V3-Base và có sẵn để tải xuống dưới các phiên bản tham số nhỏ hơn: 1.5B, 7B, 8B, 14B, 32B và 70B. Các phiên bản này được chưng cất (distilled) từ DeepSeek R1 lớn, dựa trên Qwen và Llama. Ngoài ra, một mô hình DeepSeek R1 671B đầy đủ cũng có sẵn để tải về. Cả R1 và V3 đều là những mô hình tương tự, nhưng khả năng suy luận vượt trội của R1 là điều khiến nó đặc biệt ấn tượng.
Các phiên bản và Yêu cầu vận hành
Cách tốt nhất để sử dụng các mô hình DeepSeek R1 và V3 671B là truy cập trang web của DeepSeek, nơi bạn có thể tạo tài khoản và sử dụng nó tương tự như ChatGPT. Các máy chủ của công ty đặt tại Trung Quốc, và một số truy vấn có thể dẫn đến câu trả lời bị kiểm duyệt.
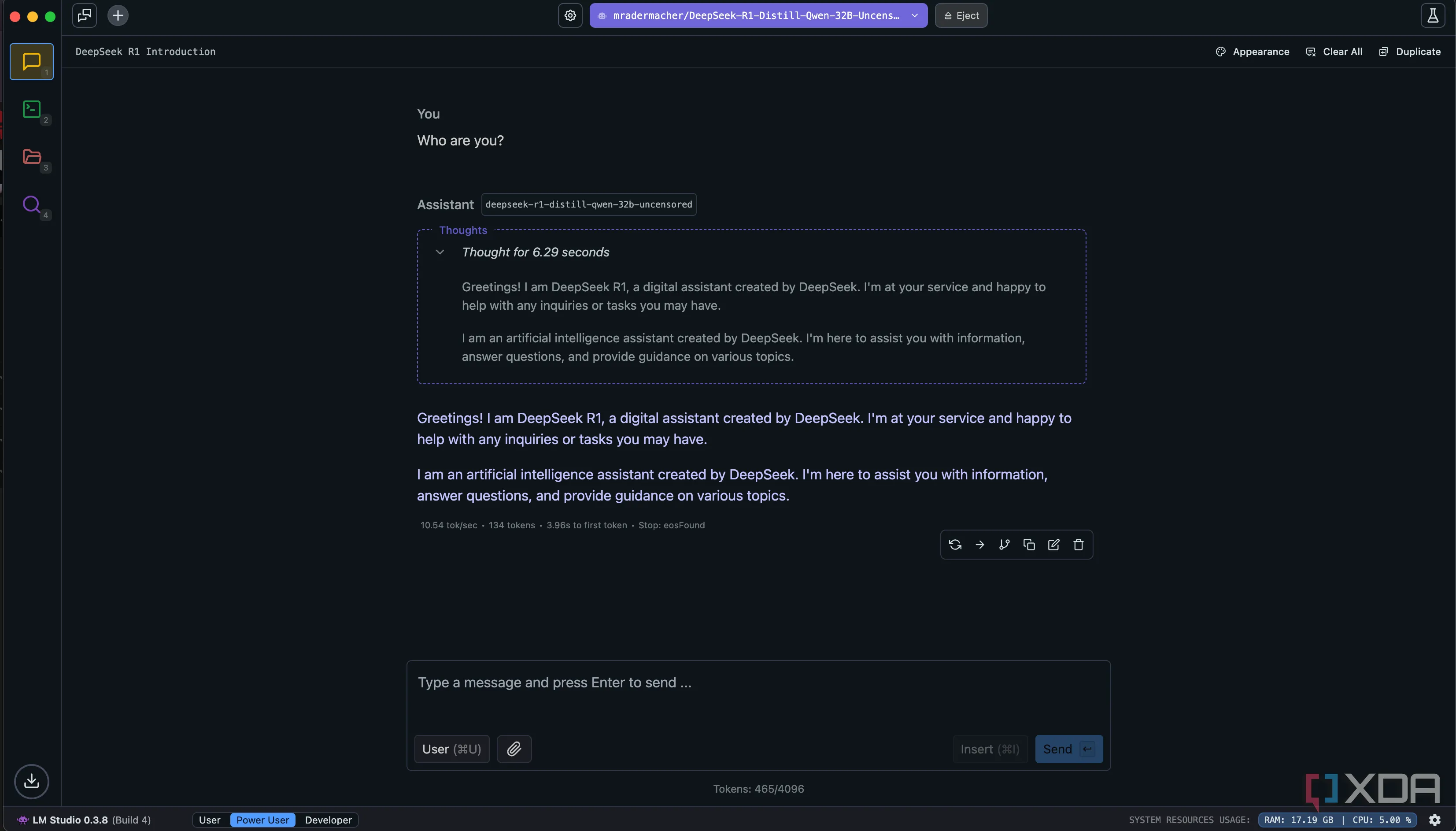 Giao diện mô hình DeepSeek R1 đang chạy cục bộ, thể hiện khả năng xử lý và tương tác người dùng trên nền tảng AI mã nguồn mở trọng số.
Giao diện mô hình DeepSeek R1 đang chạy cục bộ, thể hiện khả năng xử lý và tương tác người dùng trên nền tảng AI mã nguồn mở trọng số.
Mô hình DeepSeek R1 671B có thể chạy cục bộ, nhưng nó yêu cầu tối thiểu 800 GB bộ nhớ HBM ở định dạng FP8 để hoạt động, theo thông tin từ AWS. Đây cũng là lúc khái niệm “open weight” của mô hình phát huy tác dụng, vì bạn có thể tinh chỉnh các tham số để loại bỏ sự kiểm duyệt, với một số mô hình không bị kiểm duyệt đã có sẵn để tải xuống thông qua một quy trình gọi là “abliteration”.
Quá trình “chưng cất” (distillation) được đề cập khi nói đến các mô hình tham số nhỏ hơn có thể không quen thuộc với nhiều người. Chưng cất đề cập đến việc sử dụng một mô hình lớn hơn để huấn luyện một mô hình nhỏ hơn, trong đó mô hình lớn là “cha” và mô hình nhỏ là “con”. Mô hình con đặt ra một loạt câu hỏi cho mô hình cha, gắn nhãn các câu trả lời và học hỏi từ các phản hồi của nó. Nói cách khác, các mô hình DeepSeek R1 mà bạn có thể chạy cục bộ được phát triển dựa trên Qwen và Llama, nơi hai mô hình này đã học hỏi từ DeepSeek R1 lớn hơn.
DeepSeek R1 có “Đánh Cắp” Dữ Liệu Từ OpenAI? Sự Đạo Đức Giả Của Gã Khổng Lồ AI
Các cáo buộc và cuộc điều tra
Hiện tại, OpenAI đang đối mặt với một số vụ kiện liên quan đến việc thu thập dữ liệu mà họ đã sử dụng để huấn luyện các mô hình của mình. Tờ The Times đã kiện OpenAI, cùng với các hãng tin Canada, Intercept Media và ANI ở Ấn Độ. Có vô số vụ kiện khác nữa, và tất cả đều cáo buộc cùng một điều: OpenAI đã sử dụng dữ liệu của họ mà không được phép để huấn luyện các mô hình GPT của mình.
 ChatGPT minh họa việc giải thích chi tiết cách thực hiện một bài tập thể dục cụ thể, nhấn mạnh khả năng tạo nội dung hướng dẫn của các mô hình ngôn ngữ lớn.
ChatGPT minh họa việc giải thích chi tiết cách thực hiện một bài tập thể dục cụ thể, nhấn mạnh khả năng tạo nội dung hướng dẫn của các mô hình ngôn ngữ lớn.
Hiện tại, chưa có ai từ OpenAI chính thức đưa ra tuyên bố rằng DeepSeek đã “đánh cắp” từ họ trên kênh chính thức, nhưng cả Bloomberg và Financial Times đều đã đưa tin rằng OpenAI và Microsoft đang điều tra khả năng này. Trước hết, đây là một vấn đề đáng cười. Ngay cả khi DeepSeek có “đánh cắp” từ OpenAI, thật khó để cảm thông với một công ty cảm thấy dữ liệu của mình bị lấy đi một cách “trái phép” trong khi một phần đáng kể dữ liệu của chính họ lại được thu thập theo cách tương tự.
Trên thực tế, OpenAI đã tranh luận ủng hộ gần như chính xác những gì mà DeepSeek bị cáo buộc đã làm. “Huấn luyện các mô hình AI bằng tài liệu công khai trên internet là sử dụng hợp pháp, được hỗ trợ bởi các tiền lệ lâu đời và được chấp nhận rộng rãi. Chúng tôi xem nguyên tắc này là công bằng với người sáng tạo, cần thiết cho các nhà đổi mới và quan trọng cho khả năng cạnh tranh của Mỹ,” OpenAI từng tuyên bố trong một bài đăng trên blog.
Vô lý trong cáo buộc “chưng cất” mô hình suy luận o1
Tuy nhiên, không rõ DeepSeek có thể đã huấn luyện dựa trên những gì từ OpenAI. Mô hình suy luận o1 của OpenAI bị che giấu luồng suy nghĩ (“chain-of-thought”); khi bạn hỏi o1 một câu hỏi, nó không đưa ra toàn bộ chuỗi suy nghĩ như R1. Đó chỉ là một bản tóm tắt, và OpenAI cố tình che giấu hoạt động bên trong thực tế, thậm chí còn khẳng định rất rõ ràng rằng mọi nỗ lực nhằm moi móc thông tin này sẽ dẫn đến việc tài khoản của bạn bị cấm.
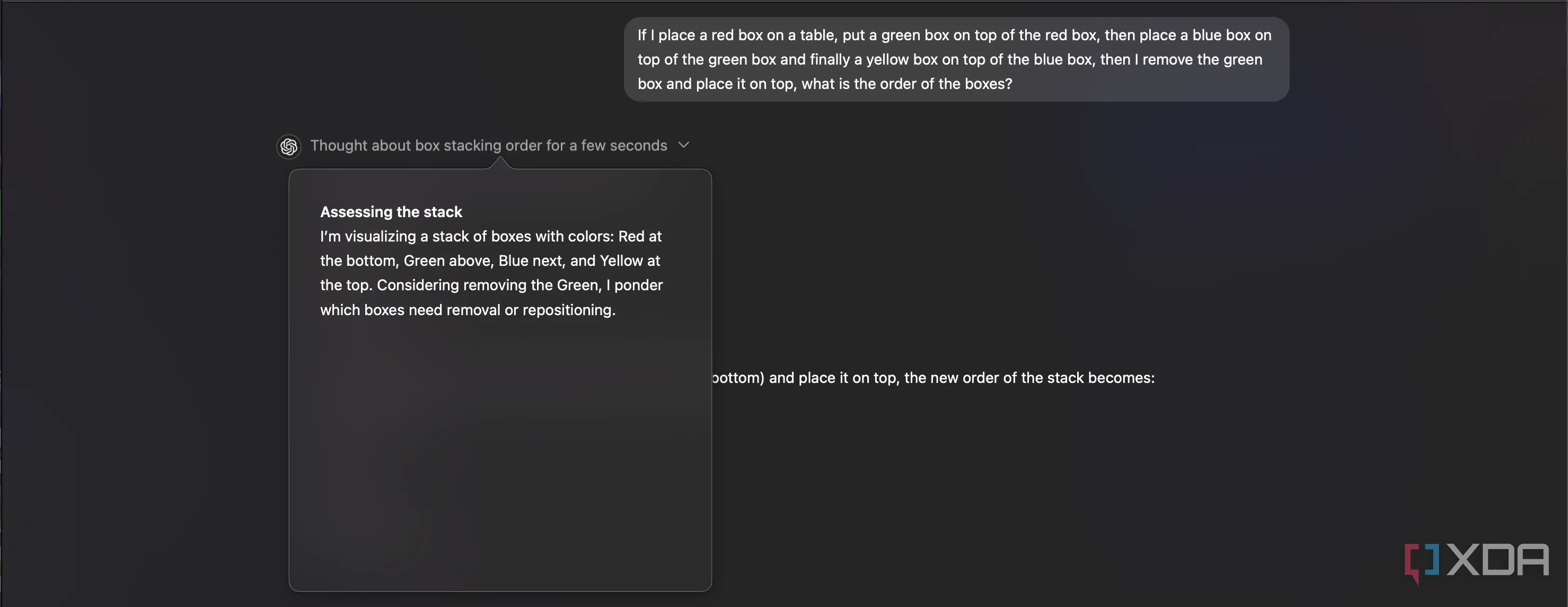 Mô hình OpenAI o1 hiển thị quá trình suy luận tóm tắt, minh họa cách o1 xử lý thông tin mà không tiết lộ chi tiết chuỗi tư duy đầy đủ.
Mô hình OpenAI o1 hiển thị quá trình suy luận tóm tắt, minh họa cách o1 xử lý thông tin mà không tiết lộ chi tiết chuỗi tư duy đầy đủ.
Không chỉ dừng lại ở đó, David Sacks, một nhà đầu tư mạo hiểm và “trùm AI và tiền điện tử” của Nhà Trắng, còn tuyên bố rằng có bằng chứng “đáng kể” về việc chưng cất R1 từ OpenAI. “Có một kỹ thuật trong AI gọi là chưng cất (distillation), mà bạn sẽ nghe nói rất nhiều, và đó là khi một mô hình học hỏi từ một mô hình khác, về cơ bản là mô hình học sinh đặt nhiều câu hỏi cho mô hình cha mẹ, giống như cách một con người học hỏi, nhưng AI có thể làm điều này bằng cách đặt hàng triệu câu hỏi, và chúng có thể bắt chước quá trình suy luận mà chúng học được từ mô hình cha mẹ và chúng có thể hút kiến thức của mô hình cha mẹ,” Sacks nói với Fox News. “Có bằng chứng đáng kể cho thấy những gì DeepSeek đã làm ở đây là chưng cất kiến thức từ các mô hình của OpenAI và tôi không nghĩ OpenAI hài lòng về điều này.”
Như chúng ta đã đề cập, quá trình suy luận này không thể được chưng cất. Chuỗi suy nghĩ bị che giấu mà mô hình o1 hiển thị cho người dùng không chứa một chuỗi suy nghĩ đầy đủ, mà thay vào đó tóm tắt những gì nó đang “suy nghĩ”. Điều này không đủ thông tin để huấn luyện DeepSeek R1, đặc biệt là khi R1 thực sự sánh ngang (và thậm chí đôi khi vượt trội) nguồn được cho là của quá trình suy luận của nó trong nhiều benchmark.
Nguồn gốc thực sự khả năng suy luận của DeepSeek R1
Với những điều đã nói, chúng ta không biết dữ liệu huấn luyện ban đầu đến từ đâu, nhưng đó không thực sự là điều mà các cáo buộc về dữ liệu bị đánh cắp liên quan đến. DeepSeek thực sự đã rất cởi mở về cách khả năng suy luận của R1 ra đời, và trong whitepaper do nhóm nghiên cứu công bố, họ cho biết rằng các khả năng này xuất hiện thông qua học tăng cường (reinforcement learning) khi xây dựng R1-Zero. Điều này tập trung vào “tự tiến hóa” (self-evolution), một kỹ thuật mà mô hình tự “học” cách đạt được mục tiêu theo cách hiệu quả nhất.
Một hiện tượng đặc biệt thú vị được quan sát trong quá trình huấn luyện DeepSeek-
R1-Zero là sự xuất hiện của một “khoảnh khắc khai sáng”. Khoảnh khắc này, như minh họa trong Bảng 3, xảy ra trong một phiên bản trung gian của mô hình. Trong giai đoạn này, DeepSeek-R1-Zero học cách phân bổ nhiều thời gian suy nghĩ hơn cho một vấn đề bằng cách đánh giá lại cách tiếp cận ban đầu của nó. Hành vi này không chỉ là một minh chứng cho khả năng suy luận ngày càng tăng của mô hình mà còn là một ví dụ hấp dẫn về cách học tăng cường có thể dẫn đến những kết quả bất ngờ và phức tạp.
Học tăng cường là một kỹ thuật học máy rất phổ biến, và neuroevolution, một phần của mô hình học tăng cường, thậm chí đã được sử dụng để dạy các mô hình cách chơi các trò chơi như Super Mario, dưới dạng MarI/O của SethBling. Đây không phải là một khái niệm mới, nhưng là một khái niệm đã bị bỏ qua phần nào khi nói đến các LLM. Rất nhiều LLM sử dụng RLHF (Reinforcement Learning by Human Feedback), nhưng RL thuần túy không yêu cầu bất kỳ sự giám sát hoặc phản hồi nào của con người.
Chi Phí Huấn Luyện DeepSeek R1: Sự Thật Đằng Sau Con Số Gây Sốc
Sự hiểu lầm về chi phí 5.576 triệu USD
Tuyên bố này bắt nguồn từ whitepaper của DeepSeek V3, trong đó nói rằng mô hình này tốn 5.576 triệu USD để huấn luyện, sử dụng 2788K giờ GPU Nvidia H800 ước tính với giá 2 USD/giờ. Đây chỉ là chi phí cho một mô hình, không phải tất cả các lần chạy thử nghiệm khác, không phải tất cả các lần họ xây dựng mô hình và sau đó phải xây dựng lại. Đây là chi phí sản phẩm cuối cùng để xây dựng mô hình, không hơn, và chắc chắn đã có nhiều khoản đầu tư đáng kể hơn vào dự án này.
Sự bỏ sót này đã dẫn đến những cáo buộc rằng DeepSeek đã nói dối về chi phí của mình, mặc dù whitepaper đã làm rõ rằng chi phí huấn luyện chỉ dành cho mô hình, không bao gồm bất kỳ chi phí chung nào khác như nghiên cứu và phát triển, các mô hình được huấn luyện trong quá trình xây dựng V3 và các chi phí liên quan khác. Đây cũng không phải chi phí của R1, mà là chi phí xây dựng V3. Eryck Banatt có một phân tích tuyệt vời về chi phí này, khẳng định rằng các con số của DeepSeek là hợp lý và nhiều khía cạnh trong tuyên bố của họ có thể kiểm chứng được ngay từ đầu.
Tác động đến thị trường và vai trò của GPU Nvidia
Tuy nhiên, những hiểu lầm cơ bản này (cùng với hiệu quả thực sự của các mô hình mới nhất của DeepSeek) và việc huấn luyện trên các GPU cũ hơn đã gây ra sự hỗn loạn thị trường. Các GPU H100 của Nvidia, được mua hàng trăm nghìn chiếc bởi các ông lớn trong không gian AI như Google, Meta và OpenAI, là những GPU mạnh nhất hiện có và trước đây được coi là cần thiết trong việc phát triển công nghệ tiên tiến.
 Chip GPU Nvidia H100, biểu tượng của sức mạnh tính toán AI cao cấp, được sử dụng rộng rãi bởi các công ty công nghệ hàng đầu.
Chip GPU Nvidia H100, biểu tượng của sức mạnh tính toán AI cao cấp, được sử dụng rộng rãi bởi các công ty công nghệ hàng đầu.
Với những điều đã nói, DeepSeek đã đạt được tất cả những điều này trên một loạt GPU H800, loại chip giảm một nửa tốc độ truyền tải giữa các chip và tuân thủ các quy định xuất khẩu trong một thời gian ngắn trước khi một lỗ hổng mà Nvidia được cho là đã lợi dụng bị đóng lại. Điều này đặt ra câu hỏi về tầm quan trọng thực sự của công nghệ mới nhất của Nvidia khi nói đến AI, nếu các GPU chậm hơn vẫn có thể cạnh tranh với kết quả của việc sử dụng những công nghệ tốt nhất.
Cáo buộc và phản bác về việc sử dụng H100
Và đó cũng là một điều khác; các cáo buộc nổi lên rằng DeepSeek đã lách các biện pháp kiểm soát xuất khẩu và mua được các GPU H100. CEO của Scale AI, Alexandr Wang, tuyên bố rằng DeepSeek có khoảng 50.000 chiếc và đã tránh nói về chúng vì điều đó sẽ chứng minh họ đã vi phạm các biện pháp kiểm soát xuất khẩu. Có khả năng Wang đã hiểu lầm một tweet từ Dylan Patel, trong đó nói rằng DeepSeek có hơn 50.000 GPU Hopper. Các GPU H800 vẫn là GPU Hopper, vì chúng là các phiên bản sửa đổi của H100 được tạo ra để tuân thủ các biện pháp kiểm soát xuất khẩu của Mỹ.
Tất cả điều này đã thúc đẩy Nvidia đưa ra một tuyên bố, nói rằng họ mong đợi tất cả các đối tác tuân thủ các quy định và sẽ hành động thích đáng nếu phát hiện họ không tuân thủ. Nvidia cũng “đã tuyên bố rằng không có lý do gì để tin rằng DeepSeek đã có được bất kỳ sản phẩm nào bị kiểm soát xuất khẩu từ Singapore,” theo Bộ Thương mại và Công nghiệp Singapore.
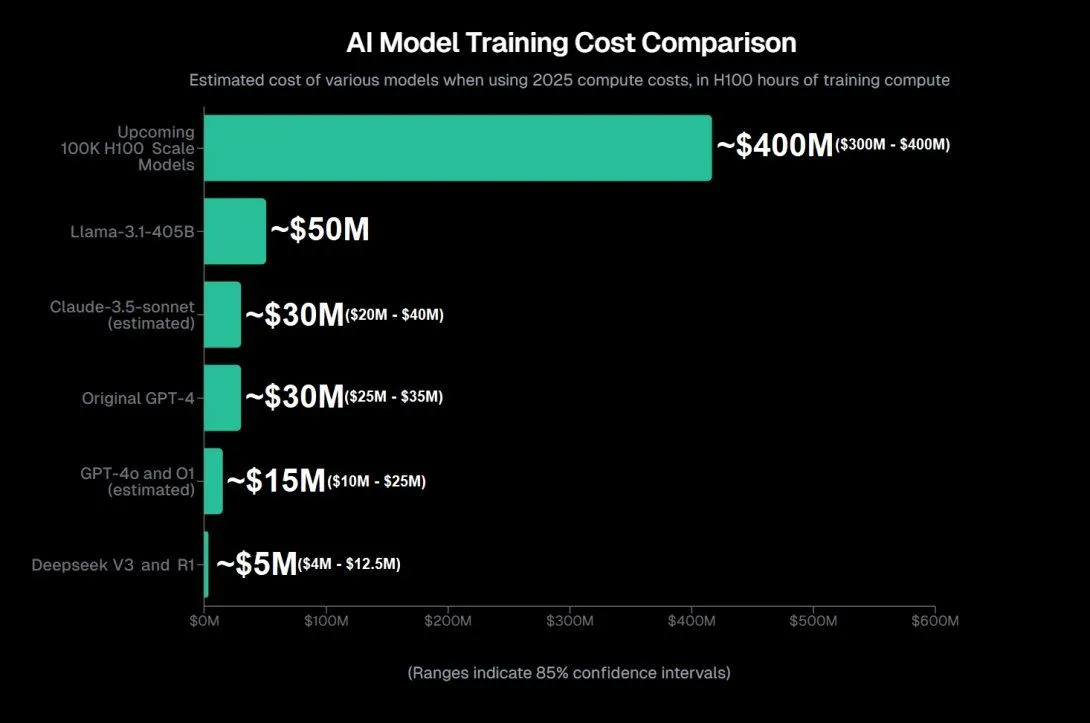 Biểu đồ so sánh chi phí huấn luyện các mô hình AI lớn do nhà nghiên cứu Aran Komatsuzaki ước tính, bao gồm GPT-4o, GPT-o1 và DeepSeek V3.
Biểu đồ so sánh chi phí huấn luyện các mô hình AI lớn do nhà nghiên cứu Aran Komatsuzaki ước tính, bao gồm GPT-4o, GPT-o1 và DeepSeek V3.
Ngay cả như vậy, chi phí này vẫn thực sự thấp. Aran Komatsuzaki, một nhà nghiên cứu AI, ước tính rằng chi phí huấn luyện GPT-4o và GPT-o1 là khoảng 15 triệu USD mỗi mô hình, gấp ba lần chi phí mô hình V3 của DeepSeek. Điều này một phần được thực hiện nhờ tối ưu hóa, vì DeepSeek đã đạt được một số tiến bộ trong lĩnh vực này. Điều đó bao gồm việc sử dụng PTX, một ngôn ngữ cấp thấp cho GPU Nvidia cho phép các nhà nghiên cứu thực hiện những việc như sử dụng một số GPU H800 để quản lý giao tiếp giữa các chip.
DeepSeek R1: Lợi Ích Khổng Lồ Cho Cộng Đồng AI Toàn Cầu
Thúc đẩy sự tiến bộ trong ngành AI
Bất chấp những ý kiến cho rằng Meta đã thành lập “phòng chiến tranh” và OpenAI có khả năng thực hiện hành động chống lại DeepSeek, đây là một chiến thắng lớn cho cộng đồng AI. Sự tiến bộ giúp ích cho tất cả mọi người, và tính “open-nature” (mở) trong nghiên cứu của DeepSeek sẽ cho phép các đối thủ sử dụng một số kỹ thuật đó để cải thiện mô hình của riêng họ. Trở lại khi tôi đề cập rằng DeepSeek là “open weights”, lý do nó là “open weights” chứ không phải “open source” là vì mã nguồn mở cũng yêu cầu dữ liệu gốc mà nó được huấn luyện.
 Ví dụ về DeepSeek R1 đang hoạt động, thể hiện khả năng xử lý thông tin và đưa ra phản hồi, minh chứng cho sự tiến bộ trong công nghệ AI.
Ví dụ về DeepSeek R1 đang hoạt động, thể hiện khả năng xử lý thông tin và đưa ra phản hồi, minh chứng cho sự tiến bộ trong công nghệ AI.
Ngược lại, “open weights” có nghĩa là chúng ta có các tham số và các giá trị số xác định cách mô hình hoạt động. Điều đó, cùng với các bài báo nghiên cứu, là quá đủ để bắt đầu khi cố gắng xây dựng một mô hình sao chép R1. Trên thực tế, một người nào đó đã và đang làm việc để xây dựng phiên bản R1 của riêng họ trong một dự án có tên “Open R1”, sử dụng tất cả thông tin được DeepSeek phát hành để triển khai nó. Dự án chưa hoàn thành, nhưng có một lộ trình và phác thảo rất rõ ràng để làm theo nếu bạn muốn tự mình thực hiện.
Giảm chi phí, tăng khả năng tiếp cận và sự minh bạch
Nếu một người bình thường như bạn hoặc tôi có thể đọc bài báo và hiểu những điều cơ bản đang diễn ra, thì bạn biết rằng các nhà nghiên cứu tại các công ty như Google, Meta và OpenAI chắc chắn có thể. Điều này sẽ cải thiện các mô hình trên toàn diện, giảm tiêu thụ điện năng, chi phí và dân chủ hóa AI hơn nữa. CEO của OpenAI, Sam Altman, đã nói rằng các mô hình suy luận của OpenAI giờ đây sẽ chia sẻ nhiều “chain of thought” hơn, cảm ơn R1 trong phản hồi của ông.
Bạn có thể chạy phiên bản chưng cất của DeepSeek R1 trong LM Studio vào thời điểm hiện tại, và tôi đã chạy mô hình Qwen 32B được chưng cất từ DeepSeek R1 trên MacBook Pro của mình với SoC M4 Pro bằng LM Studio.
Kết Luận
DeepSeek R1 và V3 đã đánh dấu những bước tiến đáng kể trong công nghệ AI, không chỉ làm chấn động thị trường tài chính mà còn thúc đẩy những cuộc tranh luận quan trọng về chi phí huấn luyện, nguồn gốc dữ liệu và tính minh bạch trong ngành. Mặc dù đối mặt với những cáo buộc và hiểu lầm ban đầu, công nghệ của DeepSeek đã chứng minh hiệu quả ấn tượng, đặc biệt là khả năng suy luận mạnh mẽ của R1 và hiệu suất trên các phần cứng có chi phí thấp hơn.
Sự xuất hiện của DeepSeek, cùng với việc công bố chi tiết kỹ thuật và mô hình “open weights”, là một lợi ích lớn cho cộng đồng AI toàn cầu. Nó không chỉ mở ra cánh cửa cho các nhà nghiên cứu và nhà phát triển khám phá và cải thiện các mô hình của riêng họ, mà còn góp phần giảm chi phí, tăng khả năng tiếp cận và đẩy nhanh quá trình dân chủ hóa công nghệ trí tuệ nhân tạo. DeepSeek R1 thực sự là một cột mốc quan trọng, định hình lại cách chúng ta nhìn nhận và phát triển AI trong tương lai. Bạn nghĩ sao về tác động của DeepSeek R1 đến tương lai AI? Hãy chia sẻ ý kiến của bạn trong phần bình luận bên dưới!